CUDA Mersenne Twister
I needed a random number generator for a CUDA project, and had relatively few requirements:
- It must have a small shared memory footprint
- It must be suitable for Monte Carlo methods (i.e. have long period and minimal correlation)
- It must allow warps to execute independently when generating random numbers
There seem to be two main approaches to RNG in CUDA:
- Each thread has its own local history, operates independently. This can be seen in the Mersenne Twister sample in the CUDA SDK (which has a very short history of 19 values). This usually requires an expensive offline process to seed each thread appropriately to avoid correlation. I can't spare the registers or local memory for this approach.
- Have a single generator per thread block, parallelise the update between all threads and synchronise using __syncthreads.
This is the approach in the recent MTGP CUDA sample.
I can't use this approach because I am allowing each warp in the block to process jobs independently (using persistent threads) - calls to
__syncthreadsto synchronise every thread in the block are not possible.
What I ended up with is basically a modified version of MTGP (the second approach above), but with each warp able to grab random numbers independently from the shared MT state. This had the nice side-effect of reducing the shared memory footprint to be the same as the equivalent CPU MT implementation.
First a quick overview of a Mersenne Twister. Each twister requires some history of at least size N, and each new entry is formed by combining the value at position -N, (-N + 1) and (-N + P) relative to the new value. The value P is fixed for a particular twister. A circular buffer of size C is used to store the history, and is usually a power of 2 so that indexing into the buffer can use trivial bitwise operations.
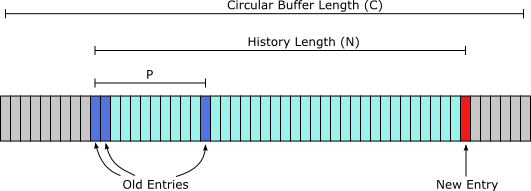
For the twisters provided by MTGP, N is large (hundreds of values) and P is small (usually in the oldest third of the history). This allows for some parallelism in the update, with two limiting factors:
- We can update at most (N - P) values in parallel. This is to ensure that the values we read during the update step have already been written.
- We can update at most (C - N) values in parallel. This is to ensure that we don't overwrite values during the update step (due to the circular buffer wrapping) that still need to be read.
A concrete example: twister 11213 from MTGP. For this twister, N=351 and (N - P) >= 256 for all parameter sets. If we use a circular buffer of size C=512, we can update at most 161 values in parallel. If we use a circular buffer of size C=1024, we can update at most 256 values in parallel.
Consider a hypothetical block of 256 threads used to update a single twister in a 1024-entry buffer in shared memory. Using the syncthreads method (option 2 listed earlier), we can update the entire circular buffer as follows:
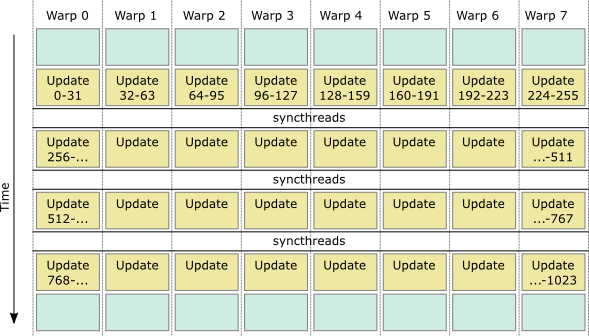
This achieves great throughput, but relies on the kernel being synchronised over all warps in the block. Unfortunately, in my use case, warps process their own jobs independently (on persistent threads), so syncthreads is not possible. What I want is for each warp to independently request some random numbers, at any time, as follows:
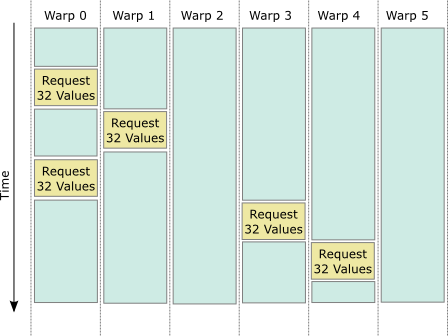
Note that this approach is only suitable if requests for random numbers are infrequent compared with other work. We have a few things to handle:
- Requests for random numbers (i.e. advancing through the history by 32 values) must be atomic, in order to handle two warps requesting numbers simultaneously. I am using atomic updates of values in shared memory for this.
- We must not update too many values in parallel (i.e. we must respect the two parallelism limits stated earlier). The current implementation ensures that only 1 warp has access to the twister state at any one time, so this is trivially enforced since we only ever update 32 values in parallel.
- The request for random numbers should not be called conditionally, if the condition is different for the threads in the warp.
This is to ensure that we update all of the 32 entries of the twister state we reserved, even if some threads of the warp don't actually need their value.
Calling code must be careful to only use conditions that are constant over the entire warp (such as
__anyconditions).
Here's the relevant code that makes it happen. It assumes that threadIdx.y can be used to access the warp index within the block, and threadIdx.x is the thread index (0-31) within the warp. The shared variable sh_mtgpReadIndex is incremented atomically from thread 0 of each warp, with the shared variable sh_mtgpWriteIndex used to serialise access to the twister state between all the warps in the block.
// some helper defines for clarity
#define THREAD_INDEX threadIdx.x
#define WARP_INDEX threadIdx.y
#define BLOCK_INDEX blockIdx.x
// the twister history
__shared__ uint32_t sh_mtgpStatus[MTGP_LARGE_SIZE];
// the current thread 0 read index in the history
__shared__ uint32_t sh_mtgpReadIndex;
// the current thread 0 write index in the history
__shared__ volatile uint32_t sh_mtgpWriteIndex;
// some shared storage for intra-warp communications
__shared__ volatile uint32_t sh_mtgpTempIndex[WARPS_PER_BLOCK];
// Generate random numbers for the entire warp
__device__ float MtgpGenerateFloat()
{
// get a read slot in the shared storage
if (threadIdx.x == 0)
sh_mtgpTempIndex[WARP_INDEX] = atomicAdd(&sh_mtgpReadIndex, THREADS_PER_WARP);
uint32_t const readIndex = sh_mtgpTempIndex[WARP_INDEX];
// wait until previous writes have completed
while (readIndex != sh_mtgpWriteIndex)
; // spin
// do the update for all threads of the warp
uint32_t const idx = readIndex + THREAD_INDEX;
uint32_t const pos = c_mtgpPos[BLOCK_INDEX];
uint32_t const r = MtgpParaRec(
sh_mtgpStatus[(idx - MTGP_SIZE) & MTGP_LARGE_MASK],
sh_mtgpStatus[(idx - MTGP_SIZE + 1) & MTGP_LARGE_MASK],
sh_mtgpStatus[(idx - MTGP_SIZE + pos) & MTGP_LARGE_MASK]);
sh_mtgpStatus[idx & MTGP_LARGE_MASK] = r;
uint32_t const o = MtgpTemperFloat(
r,
sh_mtgpStatus[(idx - MTGP_SIZE + pos - 1) & MTGP_LARGE_MASK]);
// update write index
__threadfence_block();
if (THREAD_INDEX == 0)
sh_mtgpWriteIndex = readIndex + THREADS_PER_WARP;
// done
return __int_as_float(o) - 1.0f;
}
Here's the results when applied to ambient occlusion, which is very much a worst case for sampling. Note the fact that noise is pretty constant globally, with none of the structured patterns visible in my previous path tracing post. Each pass fires 1 camera ray, which then spawns 4 independent ambient occlusion rays. The images are shown for 1/8/64/512 passes:



